
Executive Summary 🔗
AI is a throughput multiplier. Clean codebase? It accelerates. Technical debt? It amplifies the chaos. Your engineers aren't the problem. Your foundation is.
The animation below simulates different combinations of AI adoption and debt management. Each frame represents a different company's policy, culture, DNA, and fingerprint. Some combinations thrive. Some collapse. Which trajectory is yours on? Read on to find out.
Conclusion: Fund debt reduction. Protect cleanup time. Measure shipping, not typing. Teams that manage debt aggressively will dominate. Teams that don't will collapse under AI-generated bugs faster than they can fix them.
For medical device teams: same rules, higher stakes. We use agentic AI for FDA-regulated software daily. It works.
Introduction 🔗

Intended Audience: This article is for leaders who have invested in AI tools and want to see stronger results from their teams. It's also for engineers who know exactly why AI adoption is stalling but can't get leadership to listen. If you're an engineer frustrated by pressure to adopt AI without the foundation to support it, or if you are a leader frustrated by your engineering team’s lack of AI adoption, send this to article to other half.
While this article is painted with a lens from medical device software development, it is more broadly applicable to any vertical that can be influenced with software
You've made the investment. Copilot licenses. Cursor seats. Maybe a pilot with Claude or some internal tooling. The board wanted an AI strategy, so you gave them one. But your engineers aren't using it. Or they tried it for a week and went back to their old workflows. Or they use it, but only for "simple stuff." When you ask why, you get vague answers. "It doesn't understand our codebase." "It makes more work than it saves." "I spend more time fixing its mistakes than writing the code myself."
Meanwhile, your LinkedIn feed is full of founders claiming 10x productivity gains. Klarna replaced 700 customer service agents with AI. Duolingo cut 10% of contractors. VCs are funding AI-native startups that ship in weeks what used to take quarters. Your competitors seem to be pulling ahead, and you can see it in their release cadence.
You feel the pressure. Your board asks why the AI investment isn't paying off. Your CEO wants to know why the competition is moving faster. You've spent real money on these tools, and you're starting to wonder if you hired the wrong engineers or bought the wrong products.
Here's what nobody told you: your engineers are probably right. The tools aren't working for them. But the problem isn't the tools, and it isn't your engineers. The problem is likely your codebase and the culture that implicitly got it there.
Those success stories you're reading about? They're either greenfield projects, narrow use cases, or companies that already had their foundations in order. They're not magic. They're not even surprising once you understand what's actually happening.
AI is a throughput multiplier. It multiplies whatever system you already have. If your codebase is clean and well-architected, AI accelerates everything. If your codebase is buried in technical debt, AI amplifies the chaos. Your engineers know this intuitively. That's why they stopped using the tools.
For a long time, "clean code" was treated as a nice-to-have by management. An engineering luxury you could postpone for the next deadline. That era is over. AI has changed the economics of software development, and paying down technical debt is now a direct business imperative and is existentially important to remain competitive in the AI revolution.
About Me 🔗
I'm Yujan Shrestha, MD, Co-founder and Partner at Innolitics. I've spent 15 years building medical device software and guiding companies through FDA clearances. I've been involved in over 100 device submissions, mostly AI/ML SaMD. I've been coding since I was 8 years old. My first taste of software-enabled labor multiplication came in 4th grade when I discovered copy-paste in Windows 3.1, then the BASIC programming language. I've been obsessed with software engineering and its application to medicine ever since.
The ideas in this article come from watching the same pattern play out across my own engineering team: AI tools arrive with big promises, productivity stalls, and everyone blames the wrong thing. The teams that succeed aren't the ones with the best tools. They're the ones that finally prioritize the foundation work they'd been deferring for years.
I write about the intersection of software engineering, regulatory strategy, and AI adoption. When I'm not debugging why an AI agent invented a nonexistent API, I'm probably helping medical device software teams navigate complex technoregulatory topics to help them build medical device software and get through the FDA regulatory hurdle.

You can connect with me on LinkedIn.
The Mental Model Every Executive Needs: A New Engineer on Every Ticket 🔗

Imagine you hired a new software engineer for every task. This person has no memory of the project's history, no understanding of its quirks, nothing beyond the ticket in front of them. How well they perform depends entirely on how well the code is documented, architected, and tested. After completing the task, they're gone. A new, equally clueless engineer shows up for the next one.
That's basically how the autonomous AI coders work today. No long-term memory. No institutional knowledge. If your codebase runs on implicit knowledge, undocumented assumptions, and unwritten rules, the AI will slowly break things over time without realizing it.
The code itself has to carry all the intent. It needs to be designed for fast onboarding and resistant to misuse so that AI augmentation actually works.
The Tunnel Vision Problem 🔗
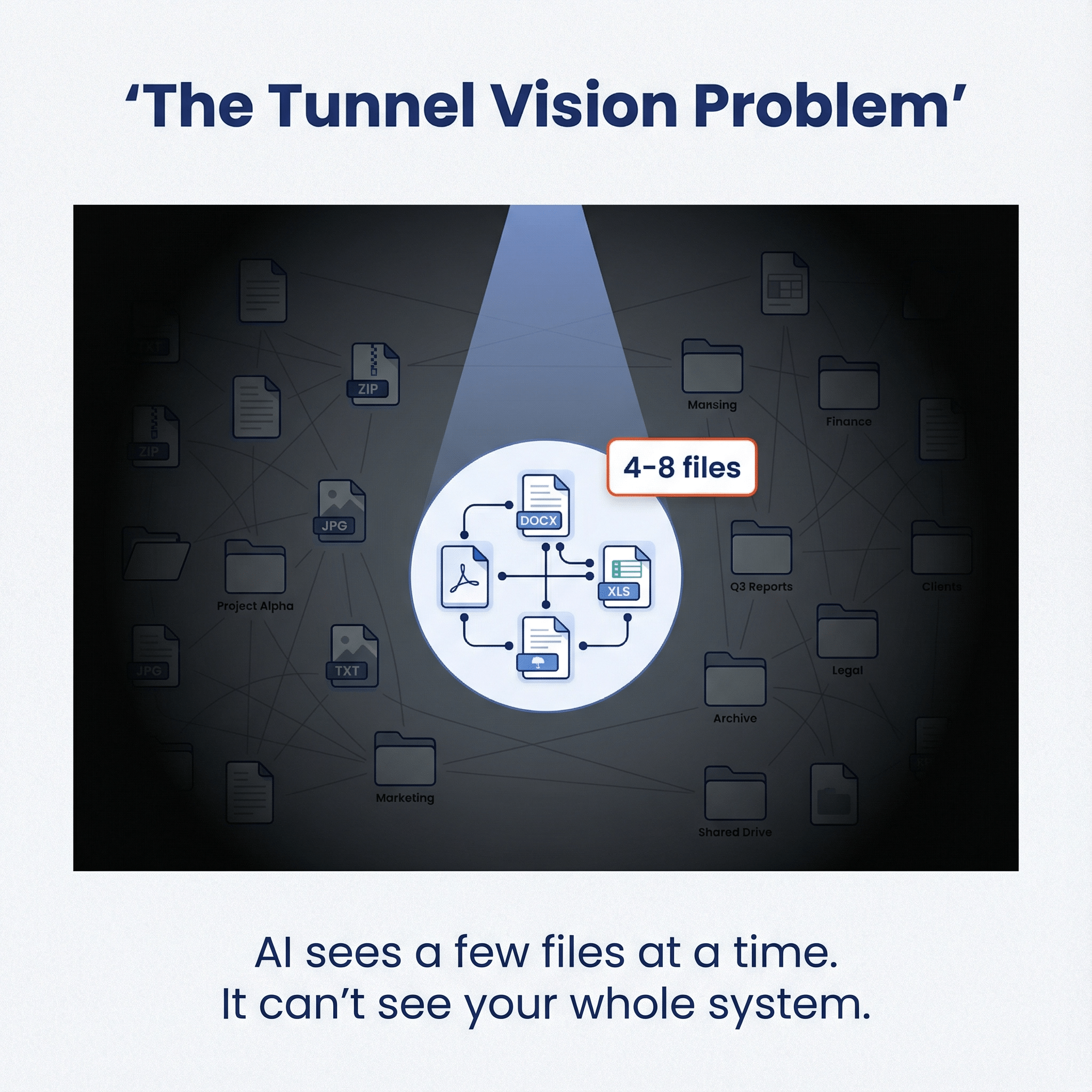
AI coding assistants can't see your whole codebase. They work through a narrow window, maybe a few files at a time. Context windows have hard limits and context rot is an issue. I don’t think this is going to change anytime soon, and even if it did, there will still be limits.
So if your codebase scatters related logic across dozens of files, the AI never sees the full picture. It makes changes that work locally but break things elsewhere. It violates contracts between components it doesn't know exist.
Locality matters. Keep related code together. Explicit interfaces beat tribal knowledge. When a module declares its inputs, outputs, and side effects clearly, the AI can work with it in isolation.
There's also the problem of unknown unknowns. A senior engineer who's new to a module still has a mental map of the broader system. They know which questions to ask. AI doesn't have that. It can't spend an hour exploring your repo before each task. It doesn't know what it doesn't know.
Documentation fixes this. Good docs turn unknown unknowns into known unknowns. A README tells the AI what exists. Architecture docs show it where to look. Comments explain why a decision was made. A failing unit test can make AI aware of business logic it inadvertently broke. The AI can drill into anything it knows about, but it can't search for things it doesn't know to search for.
Think of your documentation as a map showing the AI what's beyond its narrow window. You're not writing docs for the new hire who joins once a year. You're onboarding your AI collaborator hundreds of times a day.
Why Humans and AI Fail in the Same Way 🔗
Good software design has always been about managing cognitive load. Objectively better code needs fewer mental registers to understand. It takes less brainpower to trace through.
| Principle | Traditional Explanation | What It Really Means (Cognitive Load) |
|---|---|---|
| Single Responsibility | A class should have only one reason to change. | When you open a file, there's only one thing to understand. |
| DRY | Don't repeat yourself. Avoid code duplication. | One place to look. One thing to remember. |
| Separation of Concerns | Keep different aspects of the system separate. | You can reason about one thing at a time without holding the rest in your head. |
| Pure Functions | Functions should have no side effects. | Output depends only on inputs. Nothing else to track. |
| Immutability | Don't mutate state after creation. | You don't need to trace state changes across time. |
| Dependency Injection | Pass dependencies in instead of creating them internally. | Dependencies are visible at the call site. No hidden context to discover. |
| Law of Demeter | Only talk to your immediate collaborators. | You don't need to understand objects three levels away. |
| Fail Fast | Detect and report errors as early as possible. | The error is close to where you're looking. Less distance to trace. Smaller call stack, fewer things to remember. |
| Composition over Inheritance | Prefer object composition to class inheritance. | Flat structures. No climbing inheritance trees to find behavior. Less things to remember. |
| Explicit over Implicit | Make behavior obvious rather than hidden. | What you see is what it does. No mental simulation of hidden paths. |
| Keep it stupidly simple | “Simple” is better than “complex”… but why? | Fewer things to remember, less cognitive load. |
Every principle in the canon reduces to the same thing: how much do I need to hold in my head to understand this code?
We forget the details of code we wrote three years ago. Hell, we forget code we wrote three weeks ago. The real test of a codebase isn't whether it's clever. It's whether a tired engineer can parachute in at 3 AM to fix a production incident without breaking something unexpected.
Readable naming, self-explanatory function signatures, shallow call stacks, clear ownership of state. These aren't about aesthetics. They're cognitive-load reducers and concept compressors. They exist so a human brain under stress and recall bias can still reason correctly. My own struggles with short-term memory forced me to adopt these practices. I can't hold more than 4 complex, interconnected systems in my head, so I MUST write code that's simple and explicit with clean boundaries.
AI sharpens this lesson. It's the canonical context-free developer that has significant memory constraints. If you want it to be effective, simplicity and clarity have to be the law of the land.
Technical Debt Is Now a Direct AI Tax 🔗

Technical debt used to be a low-grade, chronic pain. Now it's an acute tax on every feature you build. Every piece of duplicated logic, every undocumented behavior, every gnarly branching statement becomes a trap for the AI. More rework. More bugs. Slower delivery.
The types of debt that are especially toxic:
- Undocumented Behavior: The AI can't know what the code should do, only what it does. If behavior isn't documented or tested, the AI will break it.
- Duplicated Logic: The AI will happily replicate the same bug across your codebase.
- Hidden Side Effects: Functions that modify state in unexpected ways are a nightmare to debug, for humans and AI alike.
- Deep Nesting: Code that's hard to read is hard for AI to extend correctly.
- Inconsistent Patterns: If there are five ways to do the same thing, the AI will invent a sixth.
- Missing tests: You can’t possibly remember every single business logic so you rely on tests to remind you of logic that passes or fails after the change. AI is very good at picking up testing failures and fixing them, but it is poor at predicting business logic failures and divergence in failures without tasks already in place
When AI tools hit a bad codebase, the promised productivity gains don't just fail to show up. They reverse. Your velocity collapses under the weight of cleaning up the AI's well-intentioned mistakes.
What "AI-Friendly Code" Looks Like 🔗
Here's the thing people miss: code written for maximum human productivity and code written for maximum AI productivity are the same code. The principles don't change. Clean boundaries, explicit contracts, low cognitive load. It's always been about making code easy to reason about.
The difference is tolerance. Humans are better at navigating tech debt. We can hold context across files, make educated guesses about undocumented behavior, and intuit our way through inconsistent code. We complain about it, but we manage. Even so, we have limits. Past a certain threshold of complexity, even experienced engineers slow to a crawl or start introducing bugs.
AI hits that wall much faster. It has less context, less tolerance for ambiguity, and no ability to "figure it out" the way a human can. What a human can slog through, AI will fail at completely.
This means a codebase built for a human-AI hybrid team has to be almost free of technical debt.
AI Writes Debt Too (and lots of it) 🔗
AI is worse at reading code than humans, which is why your codebase needs to be cleaner to start with. But AI is also worse at writing code. It produces more duplication, more inconsistent patterns, more subtle violations of your conventions. Humans to do this to but at a much lower magnitude. Left unchecked, AI will slowly degrade the very codebase it depends on.
This isn't a one-time cleanup. It's an ongoing process. You can't just pay down your debt once, hand the keys to AI, and walk away. The debt will creep back in, faster than before, because your code is now being written by a collaborator with no memory of the patterns you established last week.
This is why human review matters more, not less. You need more sophisticated feedback loops, not fewer. Code review has to be rigorous. Linting and automated checks have to be strict. Senior engineers need to be actively watching for drift.
Think of it like this: AI is a powerful engine, but it has no steering. Humans provide the steering. If you remove humans from the loop or let review become a rubber stamp, the engine will drive you straight into a ditch.
The teams that succeed with AI won't be the ones that automate humans out of the process. They'll be the ones that build tight feedback systems where humans catch debt before it spirals and continuously course-correct the AI's output.
The Mental Model 🔗
I am a visual person and I like to think about problems with graphs, charts, and diagrams. Let’s attempt to model modern software development with the following variables:
- Business value: The cumulative productive output of your software system, measured in hypothetical millions of USD. Think of it as the total value your engineering effort has created over time: features shipped, problems solved, capabilities delivered. This number grows when your team adds productive work and shrinks as the software becomes obsolete (competitors ship better alternatives, dependencies age out, user expectations evolve). It's not your company's valuation, which depends on revenue and market factors. It's the value embedded in the codebase itself.
- Productivity: How much business value is being added per week
- δ (Depreciation Rate): Software value decays over time. A δ of 0.05 means 5% of existing value becomes obsolete each week as the market evolves, dependencies change, and competitors ship new features, and software gets cheaper to build. In our model, we default this to 5% per week. This reinforces the mindset that software is never “done”
- Debt_t (Technical Debt): A number representing how "messy" the codebase is. At 0%, the codebase is pristine. At 100%, no productive value is being delivered since all engineering effort goes into just fixing bugs introduced by high tech debt. At 120%, defects are being introduced faster than engineers can fix them which quickly leads to a total collapse.
- Human productivity = 1 - Debt_t: Let’s say your human engineering team produces $1M unit of business value per week, reduced by the current debt. If debt is 30%, our model adds $0.7M of value every week. The $0.3M goes into paying the interest on the technical debt in the form of defect cleanup, lost productivity due to lack of tests, etc.
- Technical debt cleanup week: When the current week is a tech debt repayment week (set by the cleanup frequency), no business value is added but tech debt is reduced by this multiplicative factor. This means tech debt can never truly reach zero. AI can also help with technical debt cleanup so I am modeling AI as a force multiplier for both value generating and technical debt clean up weeks.
- Human tech debt per week= fixedRate + proportionalRate × Debt_t: Every non-tech debt cleanup week adds a small fixed amount of debt, plus a proportional amount that compounds with existing accumulated debt.
- AI throughput multiplier: How much faster AI is at producing value (and debt) than humans.
- AI technical debt sensitivity multiplier: How much more sensitive AI is at the detrimental effects of technical debt than humans. At 2× sensitivity, AI hits zero productivity at 50% debt (where humans would still be at 50%).
- AI productivity = AI throughput multiplier × (1 - AI technical debt sensitivity multiplier × Debt_t): AI produces more output (e.g., 2.6× throughput), but is more sensitive to technical debt.
- AI tech debt per week = throughput × sensitivity × humanDebt: AI's speed is a double-edged sword - it produces debt faster in proportion to its throughput and sensitivity.
Limitations 🔗
A famous statistician George Box once said "All models lie, some are useful."
This model is no exception. Here are some caveats:
Productivity isn't linear with debt. Real codebases have thresholds and cliffs. A team might tolerate 40% debt with minimal slowdown, then hit a wall at 45% where everything grinds to a halt. The model uses smooth curves because they're easier to reason about, but reality is messier.
Debt doesn't accumulate uniformly. Some weeks add more debt than others. A rushed feature under deadline pressure creates more mess than a carefully planned one. The model treats debt generation as steady, which flattens out the spikes that actually cause problems.
Cleanup isn't all-or-nothing. Real teams don't flip a switch between "feature work" and "debt cleanup." They do both in parallel, at varying ratios. The model's binary cleanup weeks are a simplification.
AI sensitivity varies by task. Some AI-generated code is nearly perfect. Other tasks produce garbage that takes longer to fix than to write from scratch. The model uses a single sensitivity multiplier, but real AI performance is highly context-dependent.
The numbers are made up. I don't have empirical data proving that AI is 2x more sensitive to debt, or that 5% depreciation per week is accurate. These are plausible guesses based on my experience, not peer-reviewed measurements.
So why bother?
Because the model captures the dynamics that matter. Even if the exact numbers are wrong, the relationships are directionally correct:
- AI amplifies whatever trajectory you're on
- Unchecked debt leads to collapse
- Regular cleanup creates sustainable leverage
- Early productivity gains can mask compounding problems
You don't need precise measurements to see that these patterns exist. Any engineer who's worked on a legacy codebase knows what happens when debt compounds. Any team that's tried AI on a messy repo knows it makes things worse before it makes them better.
The model is a thinking tool, not a prediction engine. Use it to build intuition about the forces at play, not to forecast exact outcomes. If it convinces you that debt management matters more in an AI-augmented world, it's done its job.
Observation #1: Managing technical debt is needed even for human only teams. 🔗
If tech debt is allowed to go unchecked (by setting the tech debt cleanup frequency to “never”), eventually the software buckles under its own weight and collapses to complete chaos. Bugs abound and the value of the software decreases over time. This is why ALL successful software heavy companies invest in tech debt clean up wether the know it or not. Otherwise, they would have never made it past the MVP stage.
Lesson: Tech debt needs to be managed. Nothing new here.
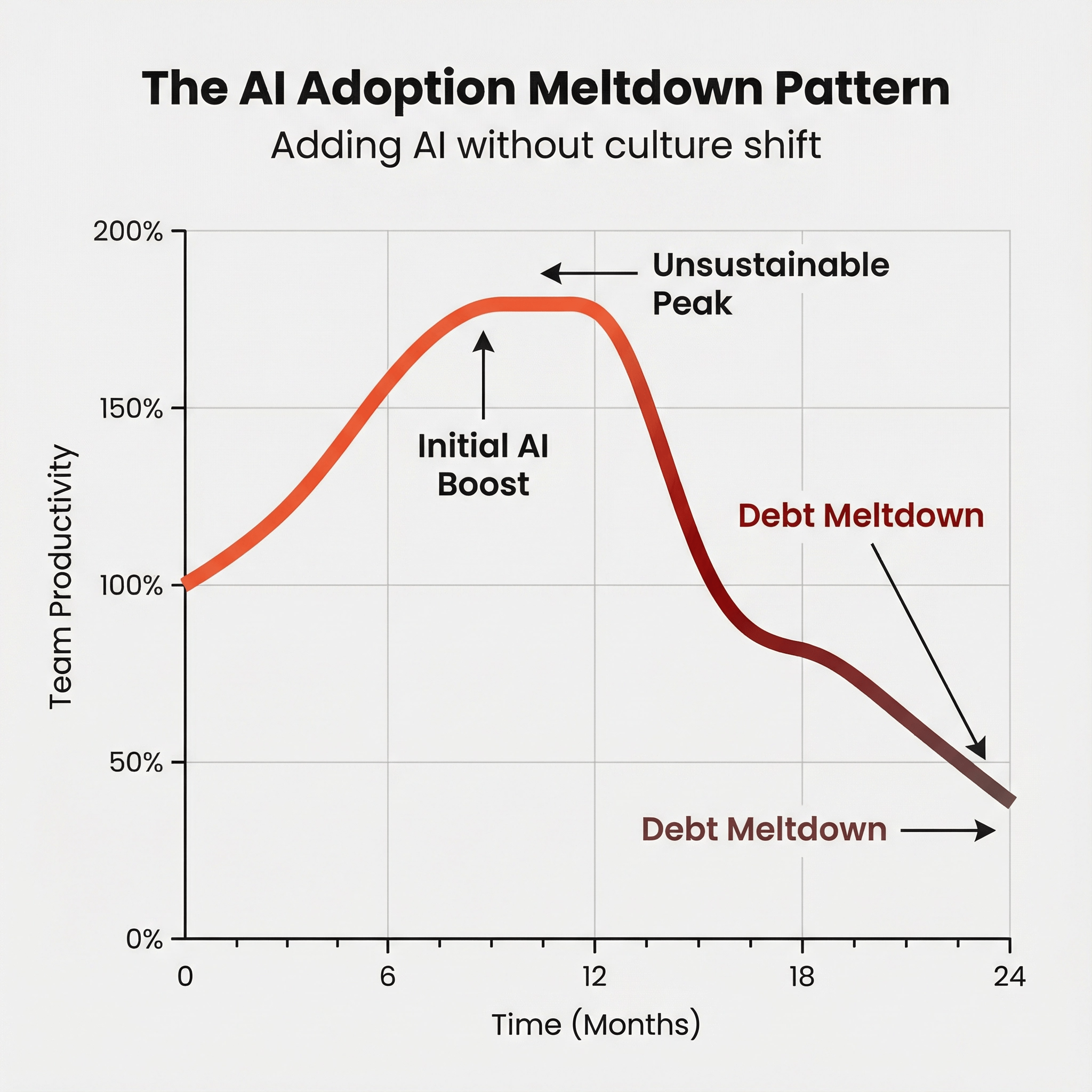
Observation #2: Just adding more AI without culture shift will result in a meltdown. 🔗
This animation sweeps the AI throughput multiplier from 0 (no AI) to 5x (AI produces five times more code than humans). Think of it as how heavily you're leaning on AI for velocity. At low values, AI helps. But as the multiplier climbs, AI-generated debt compounds faster than teams can manage. The result is a death spiral where productivity collapses under its own weight.
Particularly worrisome is the initial boost in productivity is followed by either a plateau of sustainability OR a meltdown. How will you know which side of history will you lie? Trust your team. They can gauge if tech debt is increasing to unmanageable levels or is stabilizing. Steady state tech debt will likely increase with the adoption of AI. Measure and managing it so it does not get out of hand is the winning mindset.
Lesson: Don't ramp up AI adoption too fast. Early wins can mask the debt that causes a later meltdown.
Observation #3: Tech debt management is the key to succeed with AI 🔗
In this animation, the frequency of technical debt cleanup sprints are varied from 2 weeks to never. No business is valued during each tech debt cleanup week, however, you’ll see it is absolutely needed for survival. Insufficient tech debt management results in a downward spiral where more work adds more debt and eventually debt destroys value by introducing bugs, massive downtime, or worldwide operations meltdown like the Southwest Airlines incident.
Lesson: A culture that aggressively cleans up technical debt will get the most out of AI and will leave the competition in the dust
Why Your Engineers Are Grieving (Yes, Really) 🔗

Before we talk about winning over your team, you need to understand what they're actually going through. It's not stubbornness. It's not technophobia. It's grief.
Engineers are facing a fundamental shift in how their profession works. Many spent years—sometimes decades—mastering a craft. Their self identity is tied to the craft. They take pride in elegant solutions, in knowing the right pattern for the right problem, in the hard-won intuition that lets them spot bugs before they happen. Now they're being told that an AI can do much of that work, and do it faster.
This isn't just a workflow change. It's an identity disruption. And humans respond to identity disruption the same way they respond to any significant loss: they grieve.
The Kübler-Ross model describes five stages: denial, anger, bargaining, depression, and acceptance. You'll see all of these on your engineering team right now. The engineer who insists AI code is "garbage" and refuses to try it? Denial. The one who's furious about "another management fad"? Anger. The senior dev who'll "maybe use it for boilerplate"? Bargaining. The quiet one who seems disengaged and wonders why they bothered learning all this? Depression.
These aren't character flaws. They're human responses to perceived loss. And if you push harder without acknowledging what's happening, you'll make it worse.
The good news: grief has a trajectory. People move through it. Your job as a leader is to create conditions that help them move forward rather than get stuck. That means:
- Don't dismiss their concerns. When an engineer says AI code isn't good enough, they're right. Acknowledge the legitimate criticism before showing them the trajectory.
- Give them agency. Top-down mandates feel like having something done to them. Invite engineers into the process of figuring out how AI fits into your workflow.
- Reframe the identity question. The craft was never "writing code." It was solving problems. Code is just the medium. AI handles more of the mechanical translation; engineers can focus on the thinking that actually matters. It is not much different than what assembly language did to punchcards, then what compilers did to assembly language, and now what spec driven development is doing to code construction.
- Celebrate the veterans. A 20-year engineer reviewing AI output catches bugs that juniors miss. Their intuition isn't obsolete—it's the quality filter that makes AI safe to use.
- Reassure the juniors. They're scared they'll never develop real skills if AI does all the work. They're wrong, but the fear is reasonable. Junior engineers who learn to work with AI will develop judgment faster, not slower. They'll see more code patterns in a month than previous generations saw in a year. The learning curve hasn't disappeared—it's shifted from syntax to architecture, from typing to thinking. Their career isn't being cut short. It's being accelerated.
The engineers who reach acceptance don't just tolerate AI. They become force multipliers. But they have to get there on their own timeline, with your support rather than your pressure.
Helping Engineers Through the Five Stages 🔗
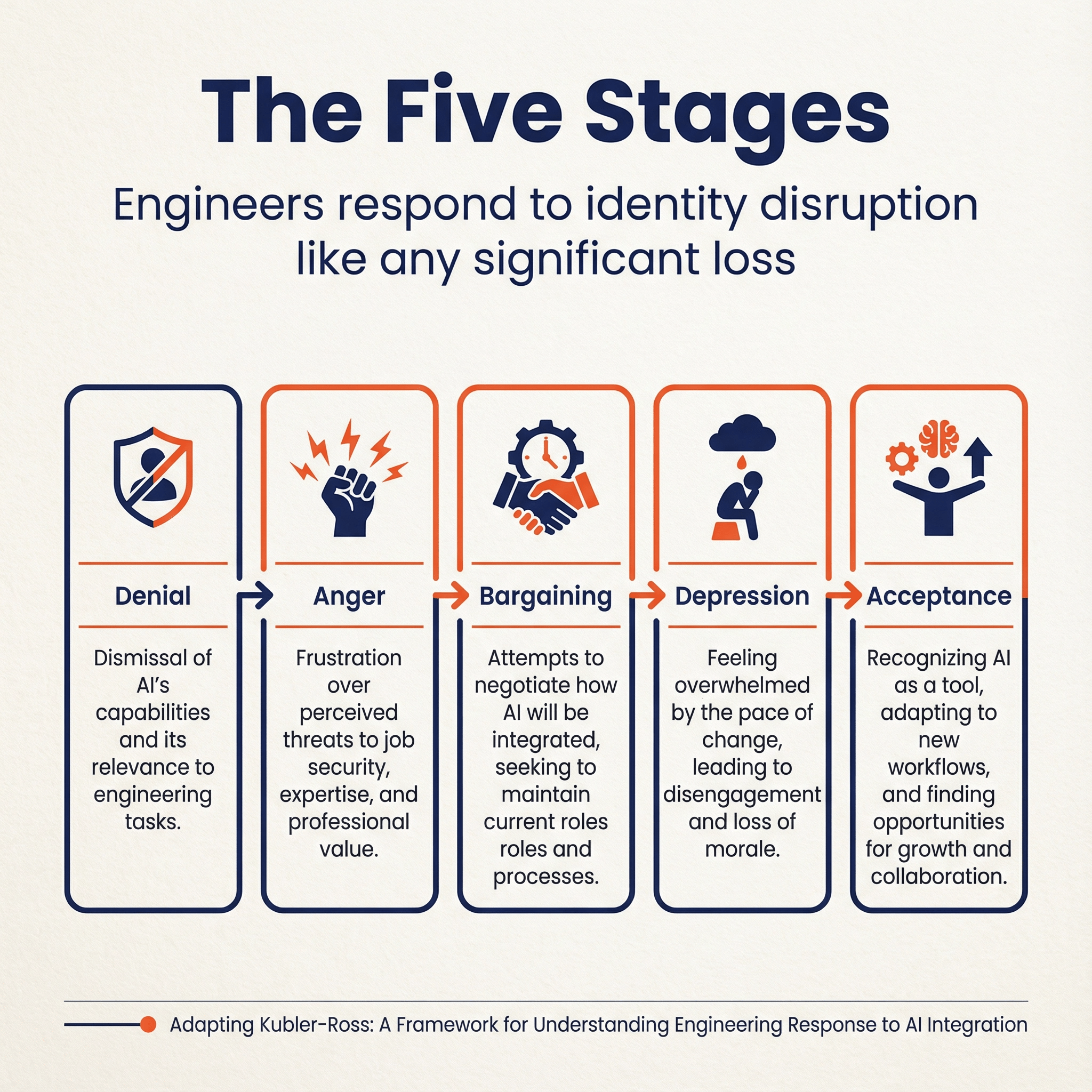
Engineers facing AI adoption often move through something like the stages of grief. Recognizing where someone is can help you meet them with the right conversation.
Winning Over Your Team 🔗
For years, engineers have fought for time to address technical debt. Management usually says new features are the priority. This has been a constant source of friction.
Your team's resistance to AI tools might not be about AI at all. It might be frustration with being asked to build on a shaky foundation. Senior engineers know the pain of messy codebases. They slow down to be careful. AI just plows ahead and makes the mess worse.
Here's the opportunity: by funding technical debt paydown, you're not just enabling your AI tools. You're solving one of your engineers' longest-standing frustrations. You're telling them you finally get why code quality matters.
When debt is no longer dragging down their daily work, engineers will be far more willing to embrace tools that help them build on a solid foundation. Funding debt reduction is a gesture of goodwill that aligns what management wants (AI-driven velocity) with what engineers want (a maintainable system).
What you'll find through this exercise is you will end up with engineers that are happier, that embrace AI, and are 30-80% more productive than before. What will you do with that extra capacity? You're going to write more software!
Jevons' Paradox and the Layoff Fear 🔗

There's another fear lurking in engineering teams: if we get 50% more productive, won't they just fire half of us?
This fear is understandable but historically wrong. Jevons' Paradox, named after the economist who observed it in 19th-century coal consumption, says that when you make a resource more efficient to use, people use more of it, not less. Coal-powered engines got more efficient, and coal consumption went up, not down. The same pattern shows up everywhere.
Software is no different. Every organization has a backlog of features they'd build if they had the capacity. Internal tools that never get prioritized. Integrations that would save time but aren't worth the engineering investment at current costs. Experiments that would be valuable but take too long to run.
When your team gets more productive, that backlog doesn't shrink. It grows. Ideas that weren't worth building at old capacity suddenly become viable. The business finds new problems worth solving. Scope expands to match supply.
I've never seen an organization look at a 50% productivity gain and say "great, let's cut the team in half." What I've seen is "great, now we can finally build that thing we've been putting off for two years."
I believe the teams that take the suboptimal route will not be competitive long-term. in this AI revolution, every company becomes a software company. Every company needs software, and software needs AI-augmented human engineers
The real risk isn't layoffs. It's falling behind competitors who figure this out first.
The Executive Summary 🔗
Your engineers are not the problem. Your codebase and culture is. AI is a throughput multiplier, and right now it's multiplying your technical debt into rework, bugs, frustrated engineers, and risk you’ll end up on news as the next Crowdstrike or Southwest Airlines.
The fix isn't buying better tools or pushing harder on adoption. The fix is investing in the foundation. Technical debt that humans could tolerate is debt that AI cannot. A codebase built for human-AI collaboration has to be nearly debt-free, because AI represents the lower bound of what your system can handle.
This isn't an engineering hobby. It's AI enablement. Every dollar you spend on debt reduction is a dollar that unlocks the productivity gains you were promised when you bought those AI licenses.
Here's what to do:
- Fund debt reduction explicitly. Give real time and budget, not just permission. Emphasize the importance of clean code specifically for the enablement of AI to increase velocity and throughput.
- Give teams air cover. Protect them from feature request pressure. Their work is what makes future velocity possible.
- Measure shipping, not typing. Hold teams accountable to lead time, deployment frequency, and failure rates. Not lines of code.
- Expect happier engineers. You're solving a frustration they've carried for years. They'll embrace AI when the foundation is solid.
- Plan for more software, not fewer people. Jevons' Paradox says productivity gains expand scope. Your backlog will grow, not your layoff list.
The productivity gains from AI are real. They're just not free. The price is discipline. The reward is sustainable leverage.
Your competitors are figuring this out. The question is whether you figure it out first.
For Medical Device Software Teams: The Stakes Are Higher 🔗

Everything in this article applies to medical device software, but with additional weight.
There's a misconception floating around that agentic AI tools can't be used for medical device development. That FDA regulations somehow prohibit it, or that the risk is too high, or that AI-generated code can't be validated. This isn't true. The same principles apply. Clean code, explicit documentation, design controls, requirements capture, threat modeling, verification and validatio, rigorous review, and continuous debt paydown. The mechanics don't change just because the stakes are higher.
What does change is the cost of getting it wrong.
Medical device software doesn't just have technical debt. It has regulatory debt: outdated design controls, incomplete traceability matrices, risk analyses that haven't kept pace with the code. It has quality debt: test coverage gaps, validation shortcuts, documentation that says one thing while the software does another. These debts compound the same way technical debt does, but the collapse point isn't just a bad quarter. It's a 483 observation, a warning letter, a recall, or a patient harm event.
AI amplifies all of this. An undisciplined AI team shipping fast in a regulated environment isn't just accumulating code debt. They're accumulating compliance risk. When the auditor asks for objective evidence that a requirement was verified, "the AI wrote it" isn't an answer.
But here's the opportunity: the same discipline that makes AI work for general software makes it work for medical devices. Explicit requirements. Traceable design decisions. Automated verification. Rigorous review. Continuous cleanup. The teams that build these foundations don't just survive regulatory scrutiny. They ship faster, with fewer findings, and with confidence that their software is safe and effective. Pretty soon you are going to outcompete the rest of the industry. An AI-native medical device software company will have higher margins, lower costs, and more product than their competitors.
We use agentic AI tools in our practice. We build medical device software with them. We know how to control technical debt while maintaining compliance. We know how to structure codebases so AI can contribute safely. We know how to document and validate AI-assisted development in ways that satisfy FDA expectations. We know how human engineers work (we are one). We have been a human-only engineering team since the beginning of our existence. And we know how AI engineers work. And we know how to combine them together to augment, not replace, to accelerate, not hinder, to amplify, not burn out
We can build a medical device software for you—in record time. Or we can transform your legacy engineering team into one that is AI native and ready to take full advantage of the AI revolution.
If you're a medical device company watching your competitors experiment with AI while you're stuck debating whether it's even allowed, you're already falling behind. The question isn't whether AI can be used for regulated software. The question is whether you'll figure out how before your competitors do.
Frequently Asked Questions 🔗
IEC 62304 and AI-Assisted Development 🔗

Technical questions about using AI coding tools in regulated medical device software development.
FDA Cybersecurity and AI-Powered Medical Devices 🔗
How AI changes the cybersecurity landscape for connected medical device software.
Conclusion 🔗
The companies winning the AI race aren't the ones with the biggest budgets or the fanciest tools. They're the ones who figured out that the foundation matters most to achieve the acceleration. Clean code, disciplined debt management, and rigorous human oversight. That's what turns AI from a liability into leverage.
If you're building medical device software, the stakes are even higher. You need a team that understands both sides: what makes code AI-friendly and what makes it FDA-friendly. We've spent 14 years and 100+ device clearances learning exactly that.
Whether you need us to build your device software, get you FDA cleared, transform your existing team into an AI-native operation, or all the above, we can help. Let's talk about your specific situation and figure out the fastest path to get to market and stay on the market.
