


Developers often don’t think about database connection pools until they are having connection problems. This article explains the purpose of connection pools, how they work, and how to tune them, while remaining agnostic to a particular implementation. It also discusses other types of object pools.
Note that not all connection pool implementations will have all the configuration options discussed here. For example, the Tomcat JDBC connection pool has many more options than SQLAlchemy’s.
Database connections without a pool 🔗
On all but the smallest sites, it is usually a good idea to place your database on a separate server. This means, whenever your application server needs to query the database, it will need an open network connection to it. For web applications, there are two simple strategies for opening and closing database connections:
- Create a new connection for each query, and then close it
- Create a new connection for each HTTP request, run queries needed, and then close it.
The first approach is not very efficient, because it takes time and processing power to open and close connections. The second approach will limit the number of simultaneous requests you can respond to to the number of connections your database can support (e.g. the default in MySQL is 151, but it can go much higher). Neither approach is ideal.
Creating a new database connections is more expensive then using a connection to make a query.
This is less so with modern databases designed for the web (e.g. MySQL), however for high performance sites, the effect is still significant. Fortunately, there is a third, better, strategy for managing connection pools.
Introduction to connection pools 🔗
Given that opening database connections is expensive, it is usually a good idea to keep several connections open and ready for your application all of the time. This set of connections is called a “connection pool”. Usually these connections are opened when your application starts.
When your application needs to make a query, it can borrow an already-opened connection from the pool, and then return it when it is done making the query. In this way, your application doesn’t need to wait to create a new connection for each HTTP request or query.
As far as the pool is concerned, there are two types of connections:
- active (or busy) connections are currently borrowed by the application
- idle connections are opened to the database, but are not currently borrowed by the application.
Note that these definitions are from the pool’s perspective. An active connection may not actually be querying the database. This could happen, for example, if an application has to do some processing in middle of a database transaction.
This figure demonstrates how a connection pool works within the application and with the database:
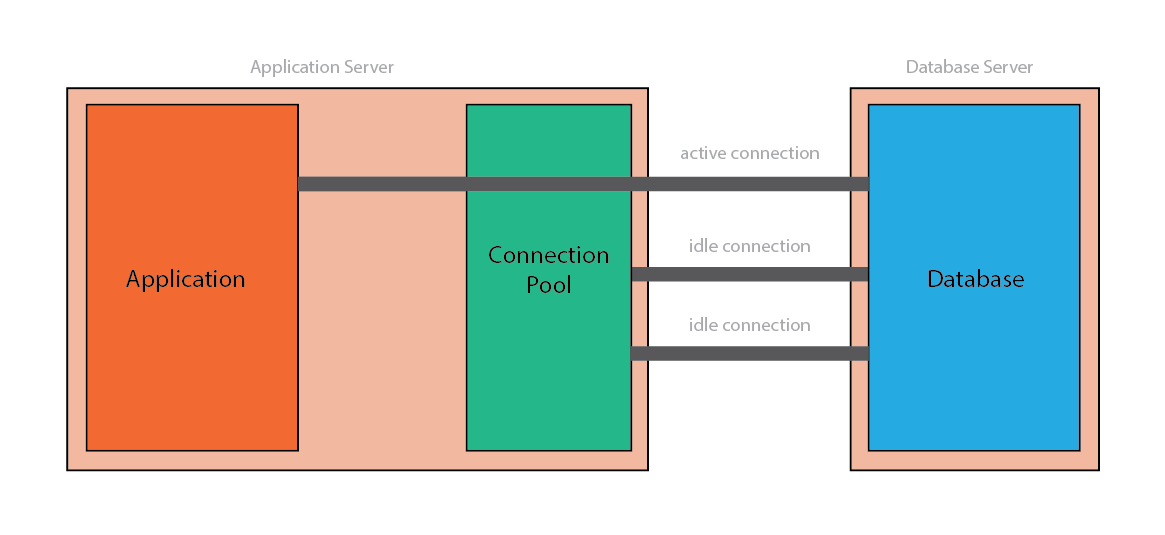
Although connection pools will improve your web application’s response time, they do bring some issues of their own, and can increase the complexity of your application. In the remainder or this article, we will talk through several issues related to connection pools.
Verifying connections are still open 🔗
Database connections can fail. Sometimes this is due to network errors, other times it is because the database server closed them directly. Because a connection pool will keep its connections open much longer than they would be if you weren’t using a pool, closed connections can become a bigger issue when using a connection pool.
A quick note on lingo: a connection that the pool considers idle could actually be closed by the database. In other words, the distinction between an idle and busy connection (with respect to the pool) is about whether it is lent out the application, and not whether it is open or closed to the database.
Connection pools alleviate the closed connection problem by periodically pinging the database with a test query. Usually this query is picked so that it is very small and fast, as it will be made frequently. Usually there are options as to when you will execute this test query. The main options are:
- just before the application borrows the connection
- just after the application returns the connection
- periodically when connections are idle.
Checking connections before lending them out provides the strongest guarantee that the connection is open, but adds the most latency. Checking connections after lending them seems mostly useless, unless you are concerned the application will somehow have closed the connection. Periodically pinging the server on each connection seems the most useful to me, but provides a weaker guarantee than checking on open. Of course you can combine these approaches.
Another related issue is connection age. Many pools can check a connection’s age, and if it is too old, close it and reopen a new one. This is useful, for example, if your database server has its own connection timeout and you want to be sure to close old connections before the database does.
Pool dynamics 🔗
How do you determine the number of connections your pool should keep open? If you have too few, the pool may run out of connections to lend to the application; if you have too many, you will be wasting application and database resources by keeping them all open (imagine if you have a 1000 connections persistently open, and they all ping the server every second). Fortunately, we can have the best of both worlds.
Most connection pools will dynamically increase and decrease the number of open connections as needed.
This is very useful for dealing with the spiky-nature of typical web applications.
When the application asks a pool if it can borrow a connection, the pool first checks if there are any idle connections available. If there are it lends it to the application (and marks it as active). If there aren’t any idle connections (and the number of active connections isn’t too high) then it will open a new connection. After a while, the pool will close extra idle connections.
The two main settings related to the size of pool are:
- Maximum number of active connections: never open more connections than this.
- Minimum number of idle connections: always keep this many connections open and free if you can.
There may also be a way to specify the maximum number of idle connections you can have, and there are many ways to specify how quickly to close extra idle connections. For example, you could close one every minute.
Setting these numbers is a balancing act and will depend on the number of web servers you have and the nature of your application. For example, if your database server can only accept 1200 connections and you have 3 web servers, you should keep the maximum number of active connections below 300. You will probably want to keep the minimum number of idle connections high enough so that the application isn’t consistency forcing the pool to open new connections.
Abandoned connections 🔗
When an application borrows a connection from the pool, it needs to be sure to return it. This is because the pool has no way of knowing that it is no longer in use, and unless told otherwise, it will just keep the connection reserved indefinitely.
A connection that is not closed by the application, but is no longer being used, is an abandoned connection. Over time, abandoned connections can accumulate and withhold all of a pool’s available connections.
Pools typically deal with this problem using timeouts; if a connection is still open after a set length of time after being borrowed, then the pool considers it abandoned, and closes it. Setting the timeout length is a balancing act. If the timeout is too short, the pool may kill connections that are actually being used, but if it is too low, you could run out of connections if your application is abandoning them very quickly. If you suspect abandoned connections are a problem, see if you can enable some sort of logging that will allow you to pinpoint what is causing your application to leak them; stopping up the leak is a much safer and better strategy for dealing with abandoned connections than depending on the pool to close them (although sometimes abandoned connections are unavoidable).
Long-running queries for reports are particularly problematic, as they will often take much longer than normal application use cases. I would recommend running reporting using a different database pool with different settings to avoid this.
Note that abandoned connection problems are not unique to database pools. In fact, they are an even bigger problem without a database pool because most databases usually have fewer configuration and logging options for dealing with them, which can make it easier to use up your connections.
NOTE: you may see articles suggesting that you decrease the connection timeout of your server. This is usually in response to your application abandoning database connections, and using up all your server’s connections. Decreasing your database’s connection timeout would be a reasonable suggestion if you are NOT using a database pool, however if you are using a database pool, it will actually cause more problems. Now your database will be closing your pool’s idle connections, forcing it to re-open them frequently. Also, unless you are verifying connections just before the application borrows them (bad for performance), it is reasonably likely the connection pool will be handing over closed connections to your application.
Other types of pools 🔗
It is interesting to note that there are other situations when it is useful to use a “pool of objects”, and in this sense it can almost be considered a design pattern.
Object pools are a useful design pattern anytime creating and destroying an object is more expensive than actually using it.
Another example besides database connections are thread pools in the apache worker module. The slab allocator—a memory allocation strategy used in the Linux kernel—is another somewhat similar example. Any time you are using a pool, you will run into analogous problems.
Conclusion 🔗
After reading this article, you should have a good conceptual model of how a database pool works. This should help you fine-tune and debug issues related to your database pool. Keep in mind, however, that often times database connection pool problems are symptoms of deeper problems, and it may be more useful to focus on tackling those first.
